Intro to R - From 0 to Tidyverse
Paul Esker; Mauricio Serrano; Mladen Cucak; Felipe Dalla Lana
Introduction
R is an open source language that was developed by Ross Ihaka and Robert Gentleman, using the S language as inspiration (source). Today R is one of the most popular tools used in data analysis and statistics.
This class will cover a basic introduction to R. Our goals are to prepare you for the next steps in the class. Please note that additional tools and functions will also be introduced as the course progress.
There are plenty of free, online resources available. Below are a few recommendations:
- R for Data Science by Garrett Grolemund and Hadley Wickham
- Advance R by Hadley Wickham
- RStudio Cheatsheets by RStudio
- Intro to R by Dr. Sydney E. Everhart, Nikita Gambhir, Dr. Kaitlin Gold, Dr. Lucky Mehra, and Dr. Zhian N. Kamvar.
- Modeling tools and techniques using R by Paul Esker and Felipe Dalla Lana
Remember, R is a software language, and as such, it requires time and practice to master what the language offers. Similar to learning a new language, once you have learned some of the basics, you will be able to continuing adding new “words” to your vocabulary and continue to build a mastery of R.
R and RStudio
R is free available to download here. R is supported by Windows, Linux, and Mac.
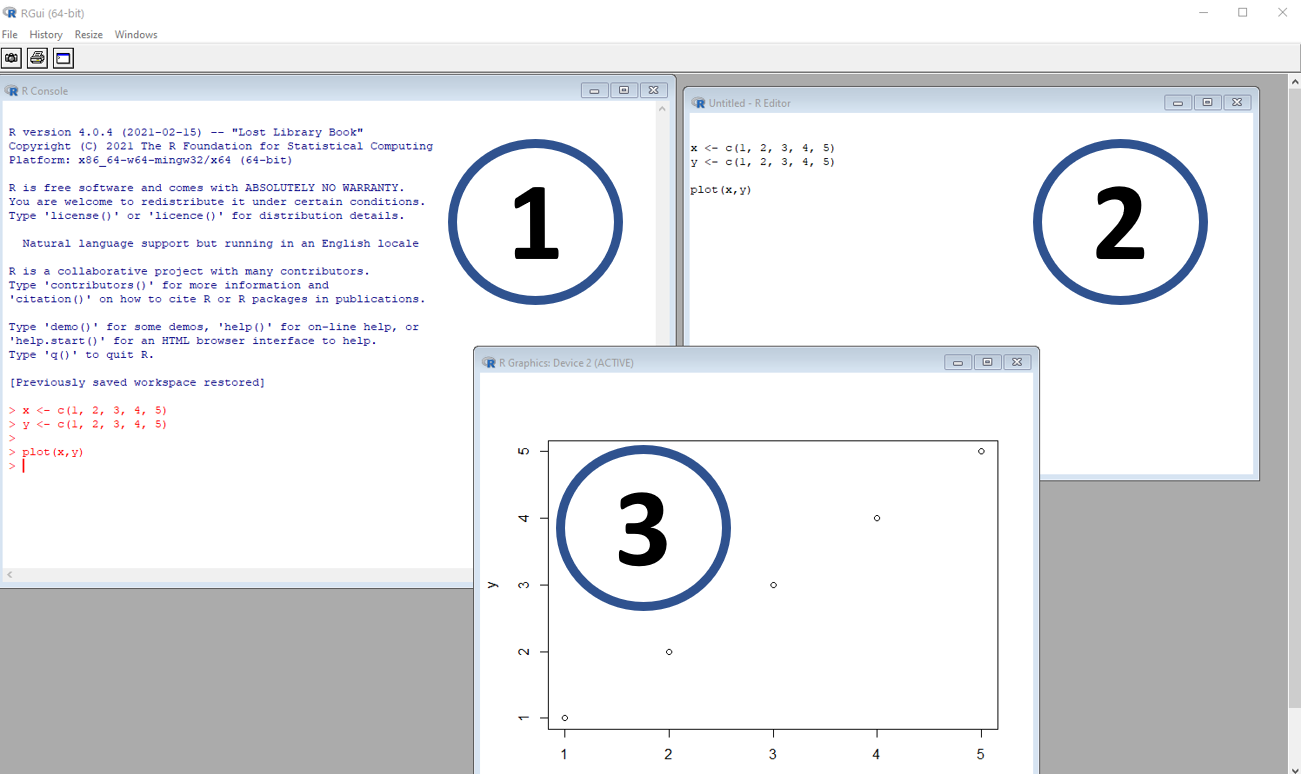
Figure, R. (1) is the console, where codes are entered and read by the software; (2) is the script or code source, where the user enters information that can be copied and pasted into the console; and (3) is a window with graph output
RStudio is the most popular IDE (Integrated development environment) used by R. It is simply a more user friendly software that integrates and runs R. It is developed by RStudio, the same location where you can download the software. The software is highly customized and includes lotos of additional “plugins”.
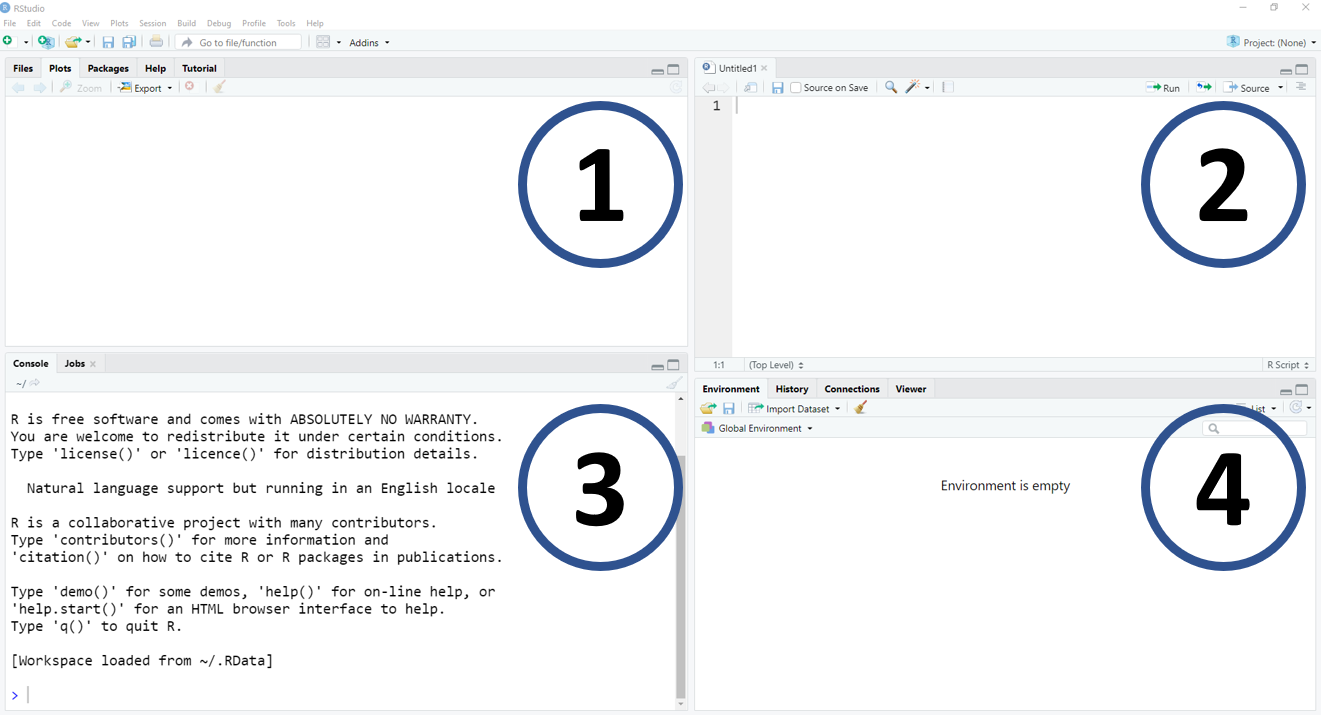
Figure, IDE-RStudio. (1) is a window with multiple pieces of information, for example, files, plots, packages, and help tools; (2) is the location of the source or script; (3) is the R console; (4) is a window with objects, coding history and more
The basic
R can be used as a simpler calculator:
# Addition
2+2## [1] 4# Subtraction
10-5## [1] 5# Multiplication
15*2## [1] 30# Division
20/10## [1] 2# Exponents
3^3 # or 3**3## [1] 27# Modulos (values that remains from the division)
10%%3## [1] 1# Integer division (fractional part is discarded)
10%/%3## [1] 3And there are many more calculations with a function like style:
# Mean
mean(c(4,10))## [1] 7# Standard deviation
sd(c(2,2,4,4,2,2))## [1] 1.032796# Square root
sqrt(9)## [1] 3# Natural log
log(100)## [1] 4.60517# Using log and defining the base (here base of 10)
log(100, base = 10)## [1] 2# Exp
exp(5)## [1] 148.4132# Absolute value (not actually a calculation)
abs(-7)## [1] 7You can assign names to objects or values, such as numbers. To do
this, use the <- or =, although the first
is preferred since it does avoid errors in very specific
situations.
# Using = to assign a value
a = 2
a## [1] 2# Or using <- to assign a value
b <- 10
b## [1] 10# Tip: Alt and - (Windows) or Option and - (Mac) are shortcut for "<-"
# You can use the assigned object to do calculations
c <- a+b
c## [1] 12# An object can also be characters
d <- "R is fun"
d## [1] "R is fun"# Can contain multiple numbers
e <- c(1,2,3,4,5) # the c means concatenate
e## [1] 1 2 3 4 5# They can be grouped into a table (more on this later)
f <- data.frame(First = c(1,2,3,4,5),
Second = c("A", "B", "C", "D", "E"))
f## First Second
## 1 1 A
## 2 2 B
## 3 3 C
## 4 4 D
## 5 5 EAlthough you can give almost any name for an object in R, there are some words that cannot be used and others that should be avoided.
# You cannot use a number as object name
1 <- 2
# Some words are reserved for specifics functions and cannot be used
NA <- 200
NaN <- 150
TRUE <-100
FALSE <- 50
Inf <- 0
# Other keywords that cannot be used as object name include:
# "break", "else", "for", "if", "next", "repeat", "return", and "while"
# You also cannot use specific keyboard symbols, such as /, @, %, !, etc.
UCR/fito <- 100
UCR@fito <- 100
UCR%fito <- 100## Error: <text>:20:4: unexpected input
## 19:
## 20: UCR%fito <- 100
## ^Some other helpful suggestions: it is good practice to label your objects in a very intuitive manner, and follow similar pattern.
For example, if you have multiple objects, such as monthly
temperature, it would be considered preferable to use something
like:temp_jan, temp_fev,
temp_mar, etc. These names are very intuitive, and follow
the same pattern (variable, underline separation, month with 3
characters), and will likely be understood for someone with some
familiarity of the data.
On the other hand, using names such as var1,
col1, Object 1, make it very difficult for
someone to understand the coding without additional information. Avoid
changing the name separation (e.g.temp_jan,
temp.feb) and take extra care with the use of
capitalization (upper and lower case letters), since R is sensitive to
this and this can often lead to errors in your code or difficulties in
running specific analyses. For example, temp_Jan,
Temp_Feb, while both work, adds an additional layer of
coding complexity that is not necessary.
When possible, we also recommend to avoid giving names to objects that are used as functions (more about functions below).
# mean() calculate the object mean
mean(c(1, 2, 3, 4, 5))## [1] 3# if you gave a name for an object of "mean", it may create awkward situations
mean <- c(1, 2, 3, 4, 5)
mean(mean)## [1] 3We can give name to plots (data visualization will be covered in the next section) and many other data formats (data frames, matrix, vector, list, etc)
# We will learn how to do better plots later, just for example here
library(ggplot2)
#plot data
data_plot = data.frame(x=c(1,2,3,4,5,6), y=c(1,2,3,4,5,6))
#plot
plot_name = ggplot(data_plot, aes(x = x, y=y)) + geom_point()
#print plot
plot_name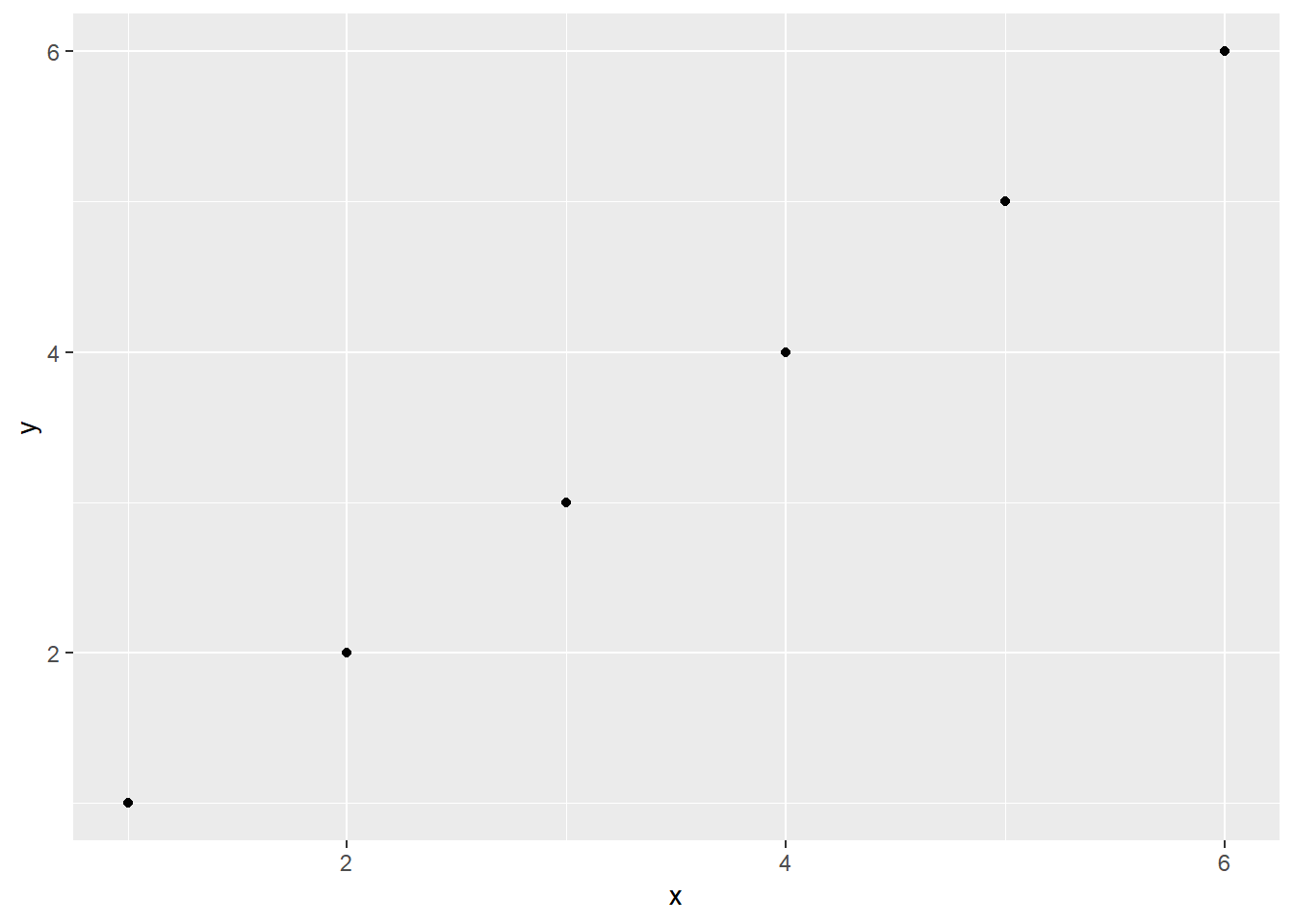
Data types and structure
Types of data
From a practical point of view, the four most important data types (or modes) are:
- Numeric = values that can be specified at the
decimal level, for example
1.2,3.141593,10.0, and-5.2; - Integer = similar to numeric, but they cannot be
defined at the decimal level. Examples of integer are
1,2,-4, an500; - Logical = can only be defined as
TRUEorFALSE, orTandFfor short; - Character = words that are like elements that are
surrounded by ” or ’, such as
"PA","Costa Rica","soybean". But, these can also refer to other numbers ("1.2",'10','-15'), or logical values ("TRUE","FALSE"); - Factor = categorical variable that contains predefined elements. Factors have levels, which determine the order of its elements. See below for examples;
- Date = elements in data format, they can be at day level (date) or date and time, including hours, minute, second, and sub-second elements (POSIXct). See below for examples;
NOTE: For practical purposes, we simplified these types of
data as part of the introduction. In R, these are called atomic vectors.
There are also two other types of atomic vectors which are rarely used
and will not be mentioned here (complex and
raw). If you would like to explore this in more detail, we
recommend Chapter 3 and 13 of Wickham book, Advanced R.
Numeric
# Lets create an example
numeric_example <- c(1.2, 1.5, 3.14, 2.7182)
# You can directly ask if the results are numeric with the function is.numeric()
is.numeric(numeric_example)## [1] TRUE# Or ask what is the class of the vector
class(numeric_example)## [1] "numeric"Integer
# Let's start by entering a vector of numbers
integer_example <- c(1,5,7,-4)
is.integer(integer_example)## [1] FALSE# If is not integer, what is the class type?
class(integer_example) ## [1] "numeric"# When you information as numbers, R will assume that is numeric
# We have to inform R that that the values are integers by using the function as.integer()
integer_exemple <- as.integer(c(1,5,7,-4))
is.integer(integer_exemple)## [1] TRUEclass(integer_exemple) ## [1] "integer"# Now, if you enter information that has decimals and force the result to be an integer,
# R will ignore the decimal information
as.integer(c(3.1, 4.9, 5.499999, 9.99999))## [1] 3 4 5 9# If you enter information as words (= class, character) and try to force this to be an integer
# R will return an error
as.integer(c("Sunday", "Monday", "Tuesday", "Wednesday"))## Warning: NAs introduced by coercion## [1] NA NA NA NA# Now, what enters when you enter numerical values in character format
number_character <- c("1", "2", "3")
class(number_character)## [1] "character"as.integer(number_character)## [1] 1 2 3class(as.integer(number_character))## [1] "integer"# This type of transformation is very useful for some data loading in R where the values can be considered as charactersLogical
# As mentioned earlier, logical values can be only be considered as TRUE or FALSE
logical_example <- c(TRUE, FALSE, T, F)
is.logical(logical_example)## [1] TRUE# Logical operations are very important for situations where you want to check specific conditions,
# for example, if one number is greater than then other
5 > 10 # five is greater than 10?## [1] FALSE"Sunday" == "Monday" # Sunday is equal to Monday?## [1] FALSE"Sunday" != "Tuesday" # Sunday is different to Tuesday?## [1] TRUE# Here is an example where R implies that the character element "2"
# should be numeric and gives the correct answer
1 < "2"## [1] TRUECharacter
# Character values are basic word elements
character_example <- c("banana", 'epidemiology', "TRUE", "11", "Character can be more than a single word")
is.character(character_example)## [1] TRUE# As you can see, they can be defined using either " or '
character_example## [1] "banana"
## [2] "epidemiology"
## [3] "TRUE"
## [4] "11"
## [5] "Character can be more than a single word"# But if you forget to include the ' or ", R will give you an error message, as R thinks that it is an object
character_example <- c("banana", epidemiology)## Error in eval(expr, envir, enclos): object 'epidemiology' not foundFactor
# Different from characters, factors are ordinal, meaning that they have a defined order or structure
factor_example <- as.factor(c("red", 'blue', "green", "red", "red"))
class(factor_example)## [1] "factor"# Note that now we have attributes (levels) with our values
factor_example## [1] red blue green red red
## Levels: blue green red# A more useful function is factor(),
# since, using this function you can define specifically the order and other attributes
factor_example2 <- factor(c("red", 'blue', "green", "red", "red"), levels = c("red", "blue", "green"))
factor_example2## [1] red blue green red red
## Levels: red blue green# Note that the order of the levels changed given that we specified the level order
# R by default uses an alphabetical ordering
# You can also change the name of the elements by changing the level label
factor_example3 <- factor(c("red", 'blue', "green", "red", "red", "yellow"),
levels = c("red", "blue", "green", "yellow"),
labels = c("RED", "Blue", "green", "green"))
factor_example3## [1] RED Blue green RED RED green
## Levels: RED Blue green# What happened? While we added a new color, yellow, we called the label "green", which means
# we redefined what yellow means. Date
# The most common date format is POSIX*
# POSIX -- describes the date and time, to the millisecond
# it takes the date in character (string) format
as.POSIXct("2021-04-05 11:30:45")## [1] "2021-04-05 11:30:45 CEST"# You can use different time zones and date formats,
# for example, we define where the date as day, month, and year,
# but in the New Zealand time zone (NZL)
as.POSIXct("25/04-2021 14:30:45",
format = "%d/%m-%Y %H:%M:%OS",
tz = "NZ")## [1] "2021-04-25 14:30:45 NZST"# Note that we used /(slash) instead of - (dash). This is only to demonstrate
# that R can deal with date information using different descriptions, which can be
# common to different weather data sources.
# Also, it is important to note that although we can use different formats,
# R still will print information using the default on ISO 8601, which means
# "year-month-day hour(24):minutes:seconds time zone"
# There are two functions which we can use: POSIXct and POSIXlt
ct <- as.POSIXct("2021-04-05 11:30:45")
lt <- as.POSIXlt("2021-04-05 11:30:45")
# both output look the same
ct## [1] "2021-04-05 11:30:45 CEST"lt## [1] "2021-04-05 11:30:45 CEST"# They are from similar classes
class(ct)## [1] "POSIXct" "POSIXt"class(lt)## [1] "POSIXlt" "POSIXt"# But, they have internally different attributes, with POSIXlt having multiple components
unclass(ct) # the big number is the total of seconds since 1970-01-01## [1] 1617615045
## attr(,"tzone")
## [1] ""unclass(lt)## $sec
## [1] 45
##
## $min
## [1] 30
##
## $hour
## [1] 11
##
## $mday
## [1] 5
##
## $mon
## [1] 3
##
## $year
## [1] 121
##
## $wday
## [1] 1
##
## $yday
## [1] 94
##
## $isdst
## [1] 1
##
## $zone
## [1] "CEST"
##
## $gmtoff
## [1] NA# It is possible to extract specific information, for example, year, month, day, etc.
weekdays(ct)## [1] "Monday"months(lt)## [1] "April"quarters(ct)## [1] "Q2"# The other class is date
dt <- as.Date("2021-04-05 11:30:45")
dt## [1] "2021-04-05"# As you can see, they are similar to POSIX* functions, however, they include only the specified information
class(dt)## [1] "Date"Data structure
Now that we understand the most important types of data, in the next section, we will learn how to group them so we can start to do different analyses. R is quite flexible in terms of grouping data. There are basically six different data structures in R:
- Scalar = a one element vector. ex.
x <- 2;y <- "beans" - Vector = a one-dimensional object with multiple scalars from the same type/mode (numeric, integer, logical, etc.)
- Matrix = a two-dimensional object that contains multiple vectors from the same type/mode
- Array = is similar to a matrix but is three-dimensional. Can only hold data from the same type.
- Data frame = are two-dimensional structures , similar to matrix, but can hold vectors from different types of data
- List = are the most complex data structure in R, and can hold a collection of objects, ranging from something as simple as a one element scale to arraya, or plots.
The figure below illustrates the differences between these five data structure types”
](figures/intro_r/data_structure.png)
Types of data structure in R. Imagen source
Vector
# You can use the function c(), which means concatenate, to create vectors
x <- c(1, 2, 3, 4)
y <- c("a", "b", "c", "d")
x## [1] 1 2 3 4y## [1] "a" "b" "c" "d"# You can select an element within a vector using brackets, [ ], along with the desired position of the element
y[3] # Will extract and provide the third element in vector y## [1] "c"Matrix
# Here an example with an matrix with numbers from 1 to 12 and dimensions of 4 rows and 3 columns
matrix_a <- matrix(1:12,ncol=3,nrow=4)
matrix_a## [,1] [,2] [,3]
## [1,] 1 5 9
## [2,] 2 6 10
## [3,] 3 7 11
## [4,] 4 8 12# To extract elements from a matrix, you have to specify first the row and then the column
matrix_a[2,3]## [1] 10# Names can be added to rows and columns by using the option 'dimnames'
matrix(1:12,nrow=4,ncol=3 ,
dimnames = list(c("A", "B", "C", "D"),
c("X", "Y", "Z")))## X Y Z
## A 1 5 9
## B 2 6 10
## C 3 7 11
## D 4 8 12Array
# Array do not have arguments for the number of rows or columns,
# but instead it uses the argument 'dim', where you provide the dimensions for row, column, and matrix
array_a <- array(1:36,dim=c(3,4,3)) #3 rows, 4 columns, 3 matrices
array_a # note that the array are actually multiple matrix## , , 1
##
## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12
##
## , , 2
##
## [,1] [,2] [,3] [,4]
## [1,] 13 16 19 22
## [2,] 14 17 20 23
## [3,] 15 18 21 24
##
## , , 3
##
## [,1] [,2] [,3] [,4]
## [1,] 25 28 31 34
## [2,] 26 29 32 35
## [3,] 27 30 33 36# You can also add row, column, and matrix names
array_a = array(1:36,dim=c(4,3,3),
dimnames = list(c("A", "B", "C", "D"),
c("X", "Y", "Z"),
c("First", "Second", "Third")))
# Similar to vector and matrix, you can extract elements by using [ ] (brackets)
array_a[2,1,2]## [1] 14# If you do not indicate one of the values, R will collect for all of the other dimensions not specified
array_a[,1,] # extract the first column from all matrix## First Second Third
## A 1 13 25
## B 2 14 26
## C 3 15 27
## D 4 16 28Data frame
# Data frames can have vector of different modes (i.e., data types)
# Numeric/character/logical
vec_numer <- c(1,2,3,4,5)
vec_chacr <- c("A", "B", "C", "D", "E")
vec_logic <- c(T, F, T, F, T)
# The function data.frame() creates new data frames
df <- data.frame(vec_numer, vec_chacr, vec_logic)
df## vec_numer vec_chacr vec_logic
## 1 1 A TRUE
## 2 2 B FALSE
## 3 3 C TRUE
## 4 4 D FALSE
## 5 5 E TRUE# The str function will show details of the data frame
str(df)## 'data.frame': 5 obs. of 3 variables:
## $ vec_numer: num 1 2 3 4 5
## $ vec_chacr: chr "A" "B" "C" "D" ...
## $ vec_logic: logi TRUE FALSE TRUE FALSE TRUE# To select an column in data.frame you can use $ signal
df$vec_chacr## [1] "A" "B" "C" "D" "E"# As well as the [ ] (brackets), similar to other data structures
df[2,2]## [1] "B"List
# A list is the most complex type of data structure and
# it can hold all previous structures mentioned before in a single object
a <- 2
b <- c(1,2,3,4,5)
c <- matrix(1:20,4,5)
d <- array(1:40, c(4,5,2))
e <- data.frame(numbers = c(1:5),
charcters = LETTERS[1:5])
first_list <- list(a, b, c, d, e)
str(first_list)## List of 5
## $ : num 2
## $ : num [1:5] 1 2 3 4 5
## $ : int [1:4, 1:5] 1 2 3 4 5 6 7 8 9 10 ...
## $ : int [1:4, 1:5, 1:2] 1 2 3 4 5 6 7 8 9 10 ...
## $ :'data.frame': 5 obs. of 2 variables:
## ..$ numbers : int [1:5] 1 2 3 4 5
## ..$ charcters: chr [1:5] "A" "B" "C" "D" ...first_list## [[1]]
## [1] 2
##
## [[2]]
## [1] 1 2 3 4 5
##
## [[3]]
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
##
## [[4]]
## , , 1
##
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
##
## , , 2
##
## [,1] [,2] [,3] [,4] [,5]
## [1,] 21 25 29 33 37
## [2,] 22 26 30 34 38
## [3,] 23 27 31 35 39
## [4,] 24 28 32 36 40
##
##
## [[5]]
## numbers charcters
## 1 1 A
## 2 2 B
## 3 3 C
## 4 4 D
## 5 5 E# You can add names to each data structure
second_list <- list(scalar = a, vector = b, matrix = c, array = d, data_frame = e)
second_list## $scalar
## [1] 2
##
## $vector
## [1] 1 2 3 4 5
##
## $matrix
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
##
## $array
## , , 1
##
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
##
## , , 2
##
## [,1] [,2] [,3] [,4] [,5]
## [1,] 21 25 29 33 37
## [2,] 22 26 30 34 38
## [3,] 23 27 31 35 39
## [4,] 24 28 32 36 40
##
##
## $data_frame
## numbers charcters
## 1 1 A
## 2 2 B
## 3 3 C
## 4 4 D
## 5 5 E# A list can include another list
third_list <- list(scalar = a, vector = b, data_frame = e, my_list = second_list)
third_list## $scalar
## [1] 2
##
## $vector
## [1] 1 2 3 4 5
##
## $data_frame
## numbers charcters
## 1 1 A
## 2 2 B
## 3 3 C
## 4 4 D
## 5 5 E
##
## $my_list
## $my_list$scalar
## [1] 2
##
## $my_list$vector
## [1] 1 2 3 4 5
##
## $my_list$matrix
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
##
## $my_list$array
## , , 1
##
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 5 9 13 17
## [2,] 2 6 10 14 18
## [3,] 3 7 11 15 19
## [4,] 4 8 12 16 20
##
## , , 2
##
## [,1] [,2] [,3] [,4] [,5]
## [1,] 21 25 29 33 37
## [2,] 22 26 30 34 38
## [3,] 23 27 31 35 39
## [4,] 24 28 32 36 40
##
##
## $my_list$data_frame
## numbers charcters
## 1 1 A
## 2 2 B
## 3 3 C
## 4 4 D
## 5 5 E# Using [ ] (brackets), we can extract different components from within the list
third_list[[3]] # Extract the third component## numbers charcters
## 1 1 A
## 2 2 B
## 3 3 C
## 4 4 D
## 5 5 Ethird_list[[3]][2] # extract the second element of the third component## charcters
## 1 A
## 2 B
## 3 C
## 4 D
## 5 EFunctions
Understanding functions
Functions are one of core components of the R language. They help to make data analyses easier, especially when trying to automate some processes.
Let’s start with a simple example:
FUN_weather <- function(x){
how_weather = paste0("Today the weather is ", x)
print(how_weather)
}
FUN_weather("good")## [1] "Today the weather is good"FUN_weather("rainy")## [1] "Today the weather is rainy"FUN_weather("hot!!!")## [1] "Today the weather is hot!!!"We can divide our functions into three components” name, arguments, and body
- Name as it suggests, it is the name of your
function. In the example above, the function is called
FUN_weather. As always, we recommend that you use names that are intuitive and follow some pattern. For example, what we did above is use FUN to indicate that this will remind us that we have created a function (or functions). The part that says weather indicates that the function will have something to do with weather. - Arguments is where we list our inputs. We start
with a call to
function()and include all arguments inside the parentheses. In our example, we have only one input,x, although it is often very common to have multiple inputs. - Body is where your arguments are used with the
additional code that you will write. The body most be within the curly
brackets
{body}. R processes functions from the first line to the last, so you can create objects that will be used later in the function, as we did in our example, creating an object calledhow_weather, which will be printed once we define the argument. The output will always be the last line of the code.
NOTE: There is one more component in the function that is environment. For the majority of the cases you don’t need to use it (~99.9% of the cases), so we will not cover this part here. But if you want to learn more, we recommend you consult Hadley Wickham’s book, Advanced R.
Adding more arguments
In the next example, the function was constructed to decide if is a
good day to go outside. For this function we use multiple arguments to
make the decision. There are a lot of new things in the code, but, for
now, let’s focus on the function itself. To be able to go outside, three
conditions must be met: (i) the temperature must be equal to or greater
than 22C (variable X); (ii) the day must be sunny; and (iii) you cannot
be busy, meaning you have the time to go outside. The function
ifelse, inside of the defined function will return “YES” if
all conditions are meet, and “NO” otherwise. This information is saved
in the object called cond. Depending on the result, this
information will be pasted in the resulting outcome called,
paste0.
FUN_go_out <- function(x = 15, y = "rain", z = "busy"){
cond <- ifelse(x >= 22 &
y == "sunny" &
z == "not_busy",
"YES", "NO")
paste0("Is it a good day to go out? ", cond)
}In addition to the multiple arguments, another difference from the
first function is the pre-defined values for the arguments. This means,
that, unless otherwise specified, the values will always take the form
of x = 15, y = "rain", and
z = "busy". Now, let’s see what happen if we run the
function without changing any of the arguments (i.e., the default).
FUN_go_out()## [1] "Is it a good day to go out? NO"In this case, R used the arguments values that defined the function, and, since none of the criteria were meet, the function output shows that it was not a good day to go out.
What if we change the parameters? What occurs now?
FUN_go_out(x = 25, y = "sunny", z = "not_busy")## [1] "Is it a good day to go out? YES"Also note that if you do not use a label for each of the arguments, R will assume that the inputs are in the same order as originally defined.
FUN_go_out(30, "sunny", "not_busy")## [1] "Is it a good day to go out? YES"Here is another example, where you label some of the inputs, but not others (in this example, the last argument is not defined). R will do as mentioned earlier in that they use the defined arguments, but then use the default argument for the missing one.
FUN_go_out(x = 30, "sunny")## [1] "Is it a good day to go out? NO"Finally, if you label the arguments, but they are ented in a different order, R will be able to follow the label of the arguments, although it is recommended to follow the defined order to minimize the potential to make a mistake.
FUN_go_out(z = "not_busy", x = 20, y = "sunny")## [1] "Is it a good day to go out? NO"So far, the examples that we showed are very simple. As we move into different methods, for example linear regression or even more complex analyses such as using a machine learning algorithm, recognize that we will have to increase the complexity of our function. As we progress through different themes, you will have the opportunity to improve your function development skills although for many of the analyses we conduct, functions will have been developed by others. This last point allows us to transition into the concept of packages, which is our next section.
Packages
What is a package?
Packages constitute the fundamental unit of what we define as
“shareable code” (Wickham 2015 -
R Packages). It is basically the easiest way to share functions and
other elements (such as data and documentation) across multiple users.
By default, R already comes with multiple packages installed, such as,
base and graphics, but there are thousands of
other packages developed by people from different backgrounds, many of
which were developed to help solve a wide array of problems.
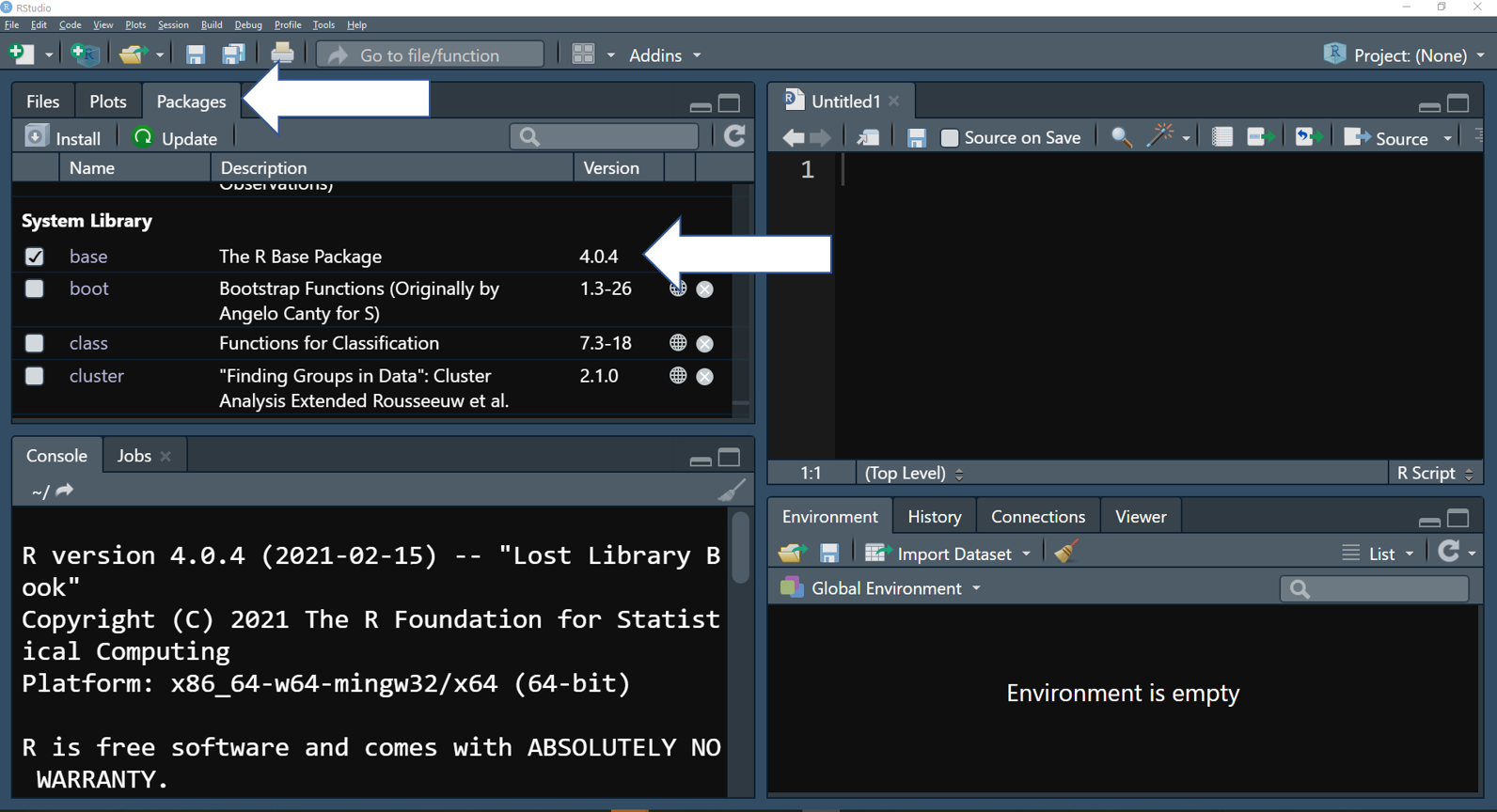
In RStudio, you can find what packages are installed in the tap “Packages”. Package name, a brief description, and version are showed
The most common way of install an package is through CRAN (Comprehensive R Archive Network), which is a network of packages held in a repository.
Let’s illustrate this with a simple example:
# To install the package called "psych"
install.packages("psych")
# Now that package is in your computer, to make the functions available to the user, we must first load this from the memory.
library(psych) # load the package
# Another way to do this is to use the function require
require(psych)Although developers try to avoid using functions with similar name, it is common that two different packages may have functions with the same name. In this case, you will see lots of codes where the author has defined the package that they are using to call the function. We will illustrate this first using a simple example.
# Take the following matrix
matrix_1 <- matrix(1:9, 3,3)
matrix_1## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9# Now, let us transpose this matrix, using the function t() from the base package (already installed and load in R)
t(matrix_1)## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9# So far, so good, but now, if we create a function called "t", we may obtain an answer we did not expect, especially since t has a very specific (and in this case, a very important) use in the R language.
t <- function(x){
x+10 } # this function adds 10 to a given value
t(matrix_1) # with this call, we will not transpose the data, rather use the function that adds 10 to a given value## [,1] [,2] [,3]
## [1,] 11 14 17
## [2,] 12 15 18
## [3,] 13 16 19# Therefore, we would need to use the following form to make sure we are using the transpose function: package name + double-colon + function
base::t(matrix_1)## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9Something very important to learn to use is the help()
function or question mark (?) plus the function name. This
provides information related to the function, as well as information
about the package where it is located.
For example ?cor.test will provide a description of cor.test function
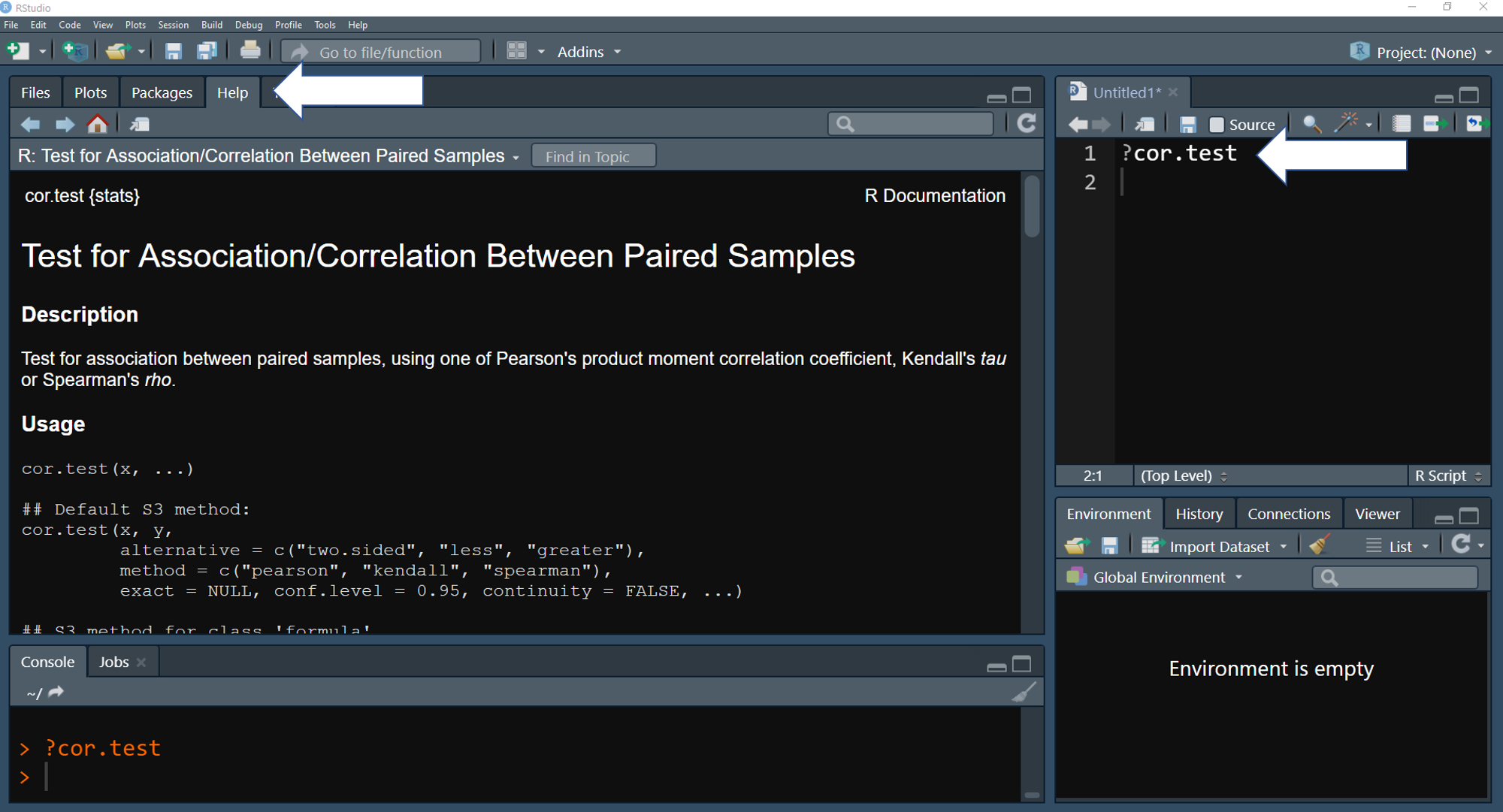
In RStudio, function description will be showed in the Help tap when use the function help() or ?
Tidyverse
When we wrote this document (2021-3-25), there were 17,371 packages available in CRAN. These packages were built by different people, with different backgrounds, focused on different types of data analyses. Naturally, there can be issues with the compatibility from one package to another. With this in mind, the developers from RStudio started to build Tidyverse, which is a group of packages that “share an underlying design philosophy, grammar, and data structures.”
There is several package that are part of tidyverse, and everyday there are more packages which share the same principles as tidyverse being added to CRAN. The “core” packages of tidyverse are:
](figures/intro_r/tidyverse.png)
Figure tidyverse. The core packages which form tidyverse. These packages
can be loaded with the following code ~ library(tidyverse).
Image
source
{kind=link}
# To install tidyverse
install.packages("tidyverse")# Load tidyverse
library(tidyverse)
During this class, we will be applying many of the tools
available in tidyverse, including in the following sections. We will
remind you about the different packages as we work through the course
materials.
Work directory and input data
Work directory
So far, all the data we have used in our examples were created
directly in R. Realistically though, we work from databases developed as
part of our research. What this means is that we will start with files
that have one of the following formats: .xlsx,
.csv, txt, etc. Furthermore, once you finish
an analysis in R, you will want to export your results and graphs. Here,
we will show how to set up R to define a specific where you will want to
store the data file and corresponding code and output. We recommend
doing this for each project to minimize errors. Before we set the
directly, let us first find out what is the default directory by using
the function getwd().
getwd() # See where the work directory is current located (Note: this will be different for each person)## [1] "C:/Git/my_old/web_epidem"If you want to change the directory, there is a couple ways to do it, and we will show two of them.
The first way to change the work directory is by using the function
setwd() (set work directory) and indicate specifically
where you want set as your “work home”.
One example showing how you might use a University-related “D”:
# Enter with the path for your work directory between ""
# setwd("D:/OneDrive_PSU/The Pennsylvania State University/Epidem class - PSU")
# NOTE: one of the most common errors for Windows users is the slash orientation. Where R uses / (forward slash), Windows use \ (backslash). A simple copy and paste, without replacing \ to /, will cause an error.Although using the function setwd() will do the job, it
is not practical. For example, if you work on two computers (one from
home and another from work or the laboratory), or if you are working on
a group project and sharing files through the something like a cloud
service (for example, Dropbox, Google Drive, etc.), every time you, and
anybody working with you, will have to change the work directory to your
computer. That is probably not very practical.
On top of that, and thinking about good practices for your work, keeping all files in the same folder with a clear pattern will help minimize errors. For all these reasons, working with projects is a much better way keep a good work flow.
Below we can see how to set up a R project.
- Think about the folder and any subfolders that you want to include in your work directory.
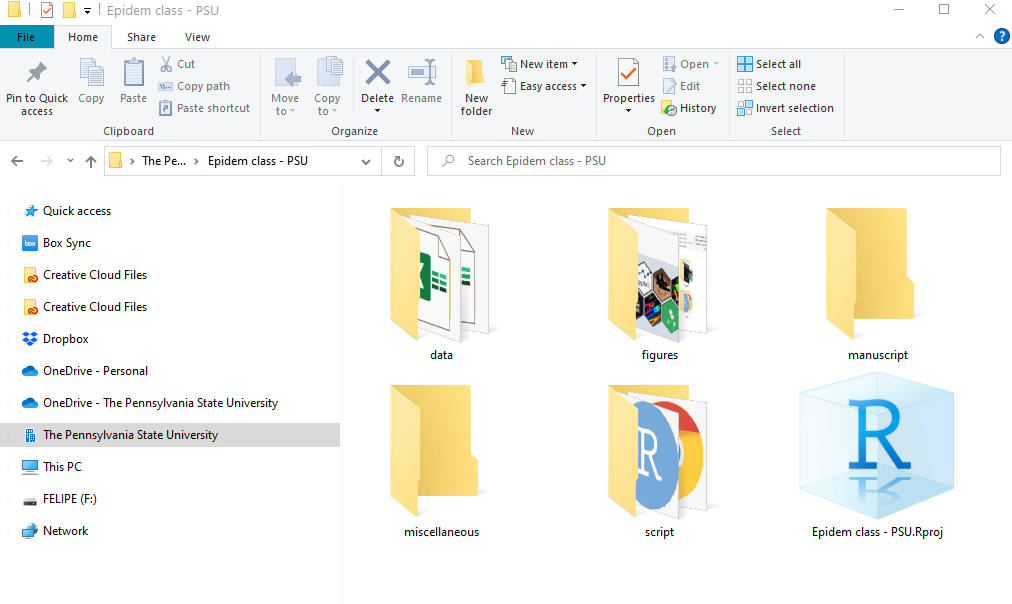
Below we can see an example, where there is a primary folder with subfolders which will have the data, figures, R scripts, manuscripts, and miscellaneous items.
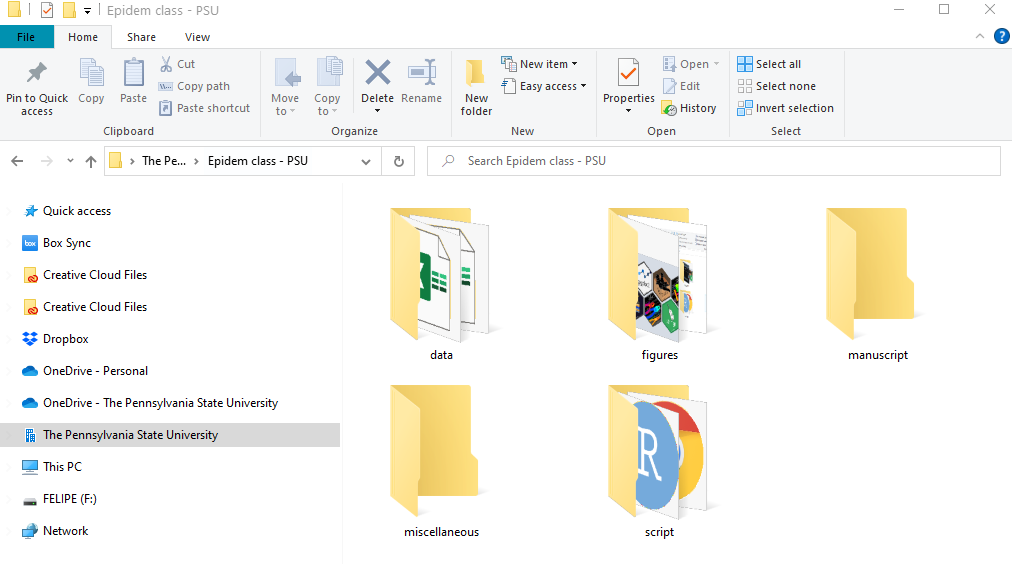
Figure folders. An example of a folder organization for creaing a R project
- In RStudio, locate in the top left the button “create a project”. A new window should open in RStudio.
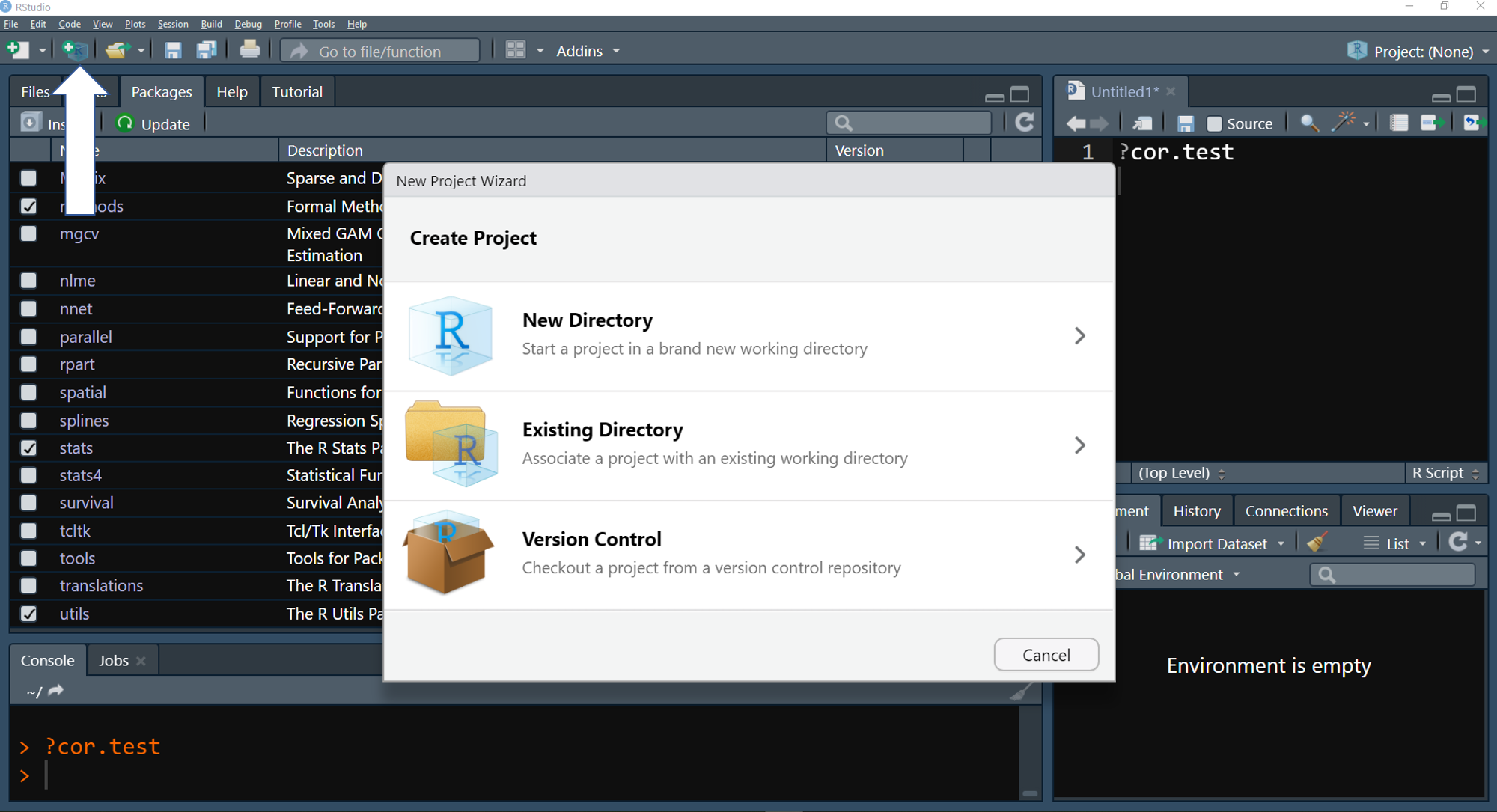
- If you already have a folder with your files, select Existing Directory and paste or browse to find your work directory path.
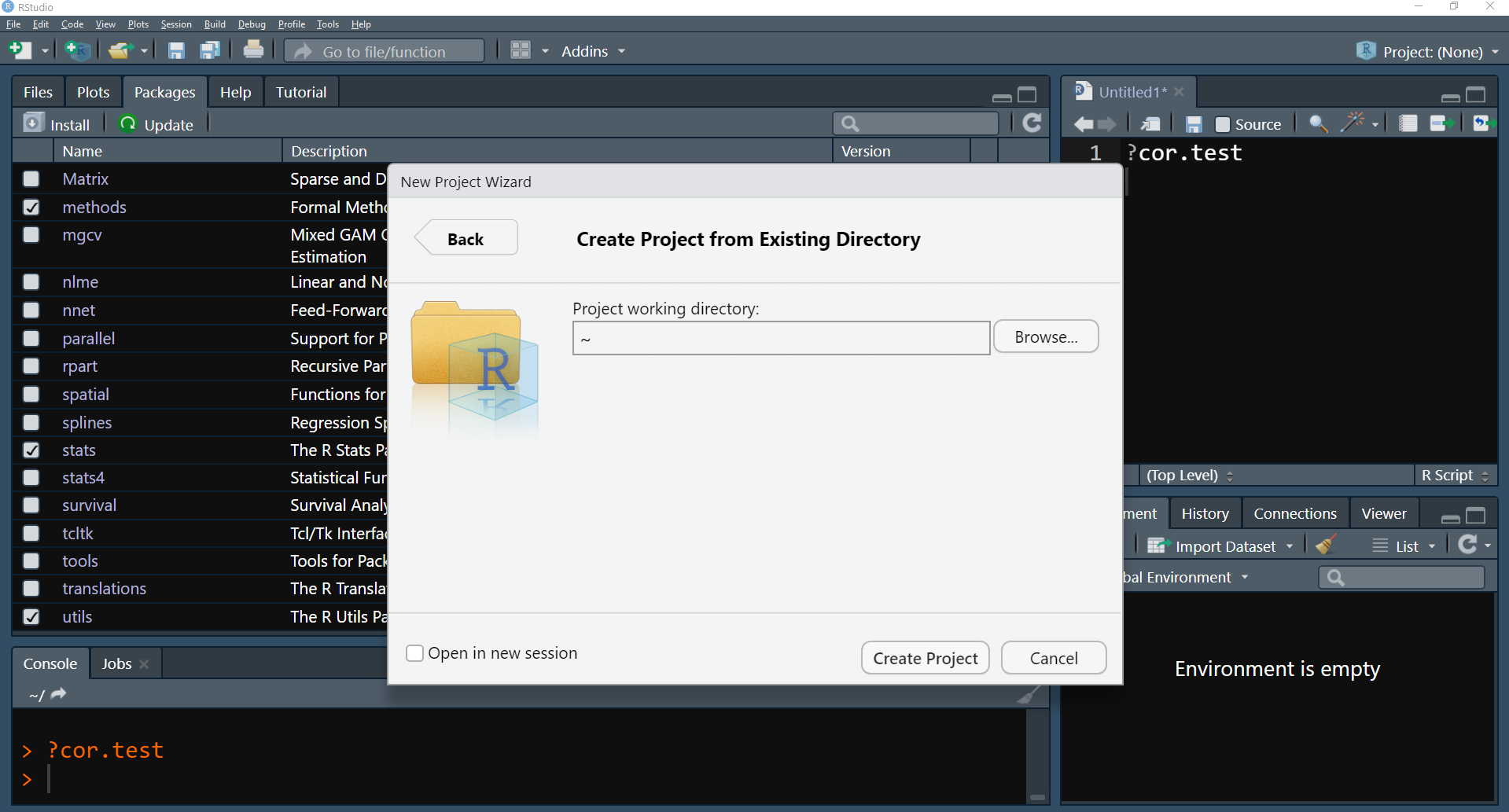
- Finally, you should have a new file in your folder, similar with the one in the example below. The next time that you use R, you can click on the file and it will open in RStudio with your work directory and previous results loaded.
Data input
Now that we have defined a project, we need to import our data into
R. In the folder data we have an file called
data_demo.csv. We will read this file into R using the
function read_csv() from the package readr
(part of core packages of tidyverse). With this function, you will be
provided directly with information about each vector (variable)
type.
# Note that because we have defined the work directory as the folder "Epidem class - PSU",
# which contains the subfolder "data", we do not have to type the entire path for the data
data_demo <- readr::read_csv("data/intro_r/data_demo.csv")## Rows: 64 Columns: 9
## ── Column specification ───────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): trt, var
## dbl (7): plot, blk, sev, inc, yld, don, fdk
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.data_demo## # A tibble: 64 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 107 A R 1 1.95 35 86.6 0.11 4
## 2 109 A R 1 1.2 20 80.3 0.15 4
## 3 204 A R 2 0.9 20 81.1 0 42
## 4 214 A R 2 4.05 50 85.1 0.07 25
## 5 305 A R 3 1.1 15 84.8 0 29
## 6 316 A R 3 1.8 10 93.7 0 24
## 7 406 A R 4 1.4 25 84.5 0.06 37
## 8 412 A R 4 0.45 10 84.8 0.07 42
## 9 108 A S 1 13.3 55 92.3 0.42 NA
## 10 110 A S 1 12.3 50 103. 0.26 NA
## # … with 54 more rowsIf you wanted to load data from another folder that is not located in our work directory, you just need to include the entire path.
# This will give you the same result, however, it is specific
# for the computer being used computer and is difficult to read
data_demo2 <- readr::read_csv("D:/OneDrive_PSU/The Pennsylvania State University/Epidem class - PSU/data/intro_r/data_demo.csv")Other functions to read .csv files include the R base
function read.csv() and read.csv2() from the
base package. For .xlsx (Excel) files, we can
use the functions read_excel(), from the package
readxl and for .txt (text) files, the function
read_table() from the package readr.
Data wrangling
Now that we have our data loaded, we often need to do some work on the data to summarize information, add new data pieces, or change the general format of the database. During this class, we will focus on ideas related to data wrangling, or data manipulation.
To expand on our initial ideas, it is often necessary to change the
shape of your data, filter the data, make specific (and documented)
changes to the data, summarize the data, as well as other options. To do
this, we will use the tools available in the tidyverse
packages, specifically tidyr and dplyr.
Before we commence with data manipulation, it is important to have a look at the data.
# We previously saw the following function, but let's use the function str() to see the details about the different variables
str(data_demo)## spc_tbl_ [64 × 9] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ plot: num [1:64] 107 109 204 214 305 316 406 412 108 110 ...
## $ trt : chr [1:64] "A" "A" "A" "A" ...
## $ var : chr [1:64] "R" "R" "R" "R" ...
## $ blk : num [1:64] 1 1 2 2 3 3 4 4 1 1 ...
## $ sev : num [1:64] 1.95 1.2 0.9 4.05 1.1 1.8 1.4 0.45 13.3 12.3 ...
## $ inc : num [1:64] 35 20 20 50 15 10 25 10 55 50 ...
## $ yld : num [1:64] 86.6 80.3 81.1 85.1 84.8 ...
## $ don : num [1:64] 0.11 0.15 0 0.07 0 0 0.06 0.07 0.42 0.26 ...
## $ fdk : num [1:64] 4 4 42 25 29 24 37 42 NA NA ...
## - attr(*, "spec")=
## .. cols(
## .. plot = col_double(),
## .. trt = col_character(),
## .. var = col_character(),
## .. blk = col_double(),
## .. sev = col_double(),
## .. inc = col_double(),
## .. yld = col_double(),
## .. don = col_double(),
## .. fdk = col_double()
## .. )
## - attr(*, "problems")=<externalptr>As you can see, there is a lot of information, but let’s focus on a
few things. First, we can see that the data dimension is 64 rows x 9
columns, and all variables are numeric, except the variables
trt and var, which are in character
format.
Now, we can use the function summary() to look at a few
summary stats, as well as the functions head() and
tail(), both of which are useful to show information about
the first and last rows in a dataset.
# Summary stats
summary(data_demo)## plot trt var blk
## Min. :101.0 Length:64 Length:64 Min. :1.00
## 1st Qu.:179.8 Class :character Class :character 1st Qu.:1.75
## Median :258.5 Mode :character Mode :character Median :2.50
## Mean :258.5 Mean :2.50
## 3rd Qu.:337.2 3rd Qu.:3.25
## Max. :416.0 Max. :4.00
##
## sev inc yld don
## Min. : 0.000 Min. : 0.00 Min. : 80.30 Min. :0.00000
## 1st Qu.: 0.300 1st Qu.: 5.00 1st Qu.: 99.65 1st Qu.:0.00000
## Median : 0.775 Median :10.00 Median :106.35 Median :0.06000
## Mean : 1.648 Mean :15.86 Mean :105.56 Mean :0.07422
## 3rd Qu.: 1.837 3rd Qu.:20.00 3rd Qu.:114.38 3rd Qu.:0.10000
## Max. :13.300 Max. :60.00 Max. :123.20 Max. :0.42000
##
## fdk
## Min. : 0.00
## 1st Qu.: 4.00
## Median : 6.50
## Mean :10.61
## 3rd Qu.:15.50
## Max. :42.00
## NA's :2# First lines
head(data_demo)## # A tibble: 6 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 107 A R 1 1.95 35 86.6 0.11 4
## 2 109 A R 1 1.2 20 80.3 0.15 4
## 3 204 A R 2 0.9 20 81.1 0 42
## 4 214 A R 2 4.05 50 85.1 0.07 25
## 5 305 A R 3 1.1 15 84.8 0 29
## 6 316 A R 3 1.8 10 93.7 0 24# Last lines
tail(data_demo)## # A tibble: 6 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 207 D S 2 0 0 113. 0.21 4
## 2 211 D S 2 1.1 20 112. 0.07 3
## 3 309 D S 3 1.25 10 117 0.15 8
## 4 314 D S 3 0.75 5 117. 0.06 3
## 5 401 D S 4 0 0 118. 0 6
## 6 413 D S 4 0.3 5 116 0.09 10From these outputs, we have a good, general idea about how the data
appear. Note that for the fourth variable called fdk
(Fusarium damaged kernels), there are two observations which are missing
and coded as NA.
In tidyverse, especially the package dplyr, there are
several excellent functions that help us to work with our data. The most
important functions can be divided in four verbs: filter,
select, mutate, and summarize.
Prior to looking at each those, we will introduction the concept of
‘pipes’. Pipes are tools available in the magrittr package
which help with the work flow. Although magrittr contains
four
different pipes, %>% is the most common and
automatically loaded when you use the tidyverse package.
What this means is that you do not need to load the package
magrittr to use the %>% pipe. See the
simple example which follows to examine how we use such a concept to
examine our data.
# Let's start with some generic data which represent values of the mycotoxin DON
DON <- c(0.1, 2.5, 7.5, 1, 0.9, 3.2, 4.5)
# If you want calculate the mean of the log-transformed values,
# a traditional way to do this is by creating multiple objects
DON_log <- log(DON)
DON_log_mean <- mean(DON_log)
DON_log_mean## [1] 0.4557823# Another way is to nest all of the functions in a single line
DON_log_nest <- mean(log(DON))
DON_log_nest## [1] 0.4557823# Finally though, we can use a pipe which provides a logical flow to work with the data, by linking the steps of the calculation and requiring fewer objects
DON_log_pipe <- DON %>% # The pipe transfer the content of the left side to right function with DON as the data, followed by the transformation and calculation of the mean
log(.) %>%
mean(.)
DON_log_pipe## [1] 0.4557823Filter
Filter is used to select rows or observations based on defined criteria
# The function filter works by defining the data source and the specific conditionn
filter(data_demo, is.na(fdk)) # is.na() will filter only rows where there is missing observations for fdk variable## # A tibble: 2 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 108 A S 1 13.3 55 92.3 0.42 NA
## 2 110 A S 1 12.3 50 103. 0.26 NA# Works with pipes as well
data_demo %>%
filter(is.na(fdk))## # A tibble: 2 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 108 A S 1 13.3 55 92.3 0.42 NA
## 2 110 A S 1 12.3 50 103. 0.26 NAWhen writing code, it is important to learn some of the important
logical operators. In our current example, we are interested in those
operators which work closely with filter().
<, less than<=, less than or equal to>, greater than>=, greater than or equal to==, equal to!=, different to!x, Not x- x
|y, x OR y - x
&y, x AND y isTRUE(x), test if X isTRUEis.na(x), test if x isNA
Let’s practice a few different types of filters.
data_demo %>%
filter(var == "R") %>% # filter only data using the column var that is defined as R (resistant in our example)
print(n=Inf) # print all observation## # A tibble: 32 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 107 A R 1 1.95 35 86.6 0.11 4
## 2 109 A R 1 1.2 20 80.3 0.15 4
## 3 204 A R 2 0.9 20 81.1 0 42
## 4 214 A R 2 4.05 50 85.1 0.07 25
## 5 305 A R 3 1.1 15 84.8 0 29
## 6 316 A R 3 1.8 10 93.7 0 24
## 7 406 A R 4 1.4 25 84.5 0.06 37
## 8 412 A R 4 0.45 10 84.8 0.07 42
## 9 112 B R 1 3.1 15 105. 0 6
## 10 114 B R 1 0.65 10 109. 0 17
## 11 209 B R 2 1.05 20 99 0.06 25
## 12 216 B R 2 2.1 25 104. 0.05 14
## 13 304 B R 3 0.8 10 107. 0 8
## 14 312 B R 3 0.45 15 104. 0 12
## 15 404 B R 4 2.5 30 101. 0 25
## 16 407 B R 4 2.95 25 105. 0 14
## 17 102 C R 1 0.65 10 105. 0 0
## 18 116 C R 1 0.3 5 107. 0.05 9
## 19 201 C R 2 0.3 10 108. 0.07 13
## 20 206 C R 2 0.3 5 98.3 0.05 16
## 21 302 C R 3 1.05 20 111. 0 4
## 22 307 C R 3 0.6 10 109. 0 7
## 23 410 C R 4 0.3 5 110. 0.06 5
## 24 415 C R 4 0.3 10 108. 0.05 18
## 25 103 D R 1 0.75 15 105. 0 4
## 26 106 D R 1 0.3 5 99.7 0.06 3
## 27 208 D R 2 1.35 40 94.6 0.06 17
## 28 212 D R 2 0.45 10 102. 0.08 11
## 29 310 D R 3 0.45 10 104. 0 18
## 30 313 D R 3 0 0 103 0.07 18
## 31 402 D R 4 0.15 5 106. 0 11
## 32 414 D R 4 0 0 107. 0.07 18data_demo %>%
filter(var == "R" & trt == "A") %>% # filter using the column var which contains R and from the column trt which contains A
print(n=Inf) ## # A tibble: 8 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 107 A R 1 1.95 35 86.6 0.11 4
## 2 109 A R 1 1.2 20 80.3 0.15 4
## 3 204 A R 2 0.9 20 81.1 0 42
## 4 214 A R 2 4.05 50 85.1 0.07 25
## 5 305 A R 3 1.1 15 84.8 0 29
## 6 316 A R 3 1.8 10 93.7 0 24
## 7 406 A R 4 1.4 25 84.5 0.06 37
## 8 412 A R 4 0.45 10 84.8 0.07 42data_demo %>%
filter(sev >= 5) %>% # filter the column severity for all values greater than or equal to 5
print(n=Inf) # print all observation## # A tibble: 5 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 108 A S 1 13.3 55 92.3 0.42 NA
## 2 110 A S 1 12.3 50 103. 0.26 NA
## 3 213 A S 2 5.5 60 93.4 0.2 6
## 4 306 A S 3 5.05 45 98 0.17 5
## 5 411 A S 4 5.65 15 99.9 0.31 7data_demo %>%
filter(fdk < 1 | don == 0) %>% # filter data from the column fdk less than 1 or from the column don where values are exactly equal to 0
print(n=Inf) ## # A tibble: 21 × 9
## plot trt var blk sev inc yld don fdk
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 204 A R 2 0.9 20 81.1 0 42
## 2 305 A R 3 1.1 15 84.8 0 29
## 3 316 A R 3 1.8 10 93.7 0 24
## 4 112 B R 1 3.1 15 105. 0 6
## 5 114 B R 1 0.65 10 109. 0 17
## 6 304 B R 3 0.8 10 107. 0 8
## 7 312 B R 3 0.45 15 104. 0 12
## 8 404 B R 4 2.5 30 101. 0 25
## 9 407 B R 4 2.95 25 105. 0 14
## 10 111 B S 1 1.65 20 112. 0 2
## 11 102 C R 1 0.65 10 105. 0 0
## 12 302 C R 3 1.05 20 111. 0 4
## 13 307 C R 3 0.6 10 109. 0 7
## 14 101 C S 1 0.3 10 122 0.08 0
## 15 115 C S 1 0.3 5 115. 0 1
## 16 301 C S 3 0 0 118. 0 1
## 17 416 C S 4 0.45 15 123. 0 4
## 18 103 D R 1 0.75 15 105. 0 4
## 19 310 D R 3 0.45 10 104. 0 18
## 20 402 D R 4 0.15 5 106. 0 11
## 21 401 D S 4 0 0 118. 0 6Select
data_demo %>%
select(trt, var, blk, sev, inc) # select multiple variables = columns## # A tibble: 64 × 5
## trt var blk sev inc
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 A R 1 1.95 35
## 2 A R 1 1.2 20
## 3 A R 2 0.9 20
## 4 A R 2 4.05 50
## 5 A R 3 1.1 15
## 6 A R 3 1.8 10
## 7 A R 4 1.4 25
## 8 A R 4 0.45 10
## 9 A S 1 13.3 55
## 10 A S 1 12.3 50
## # … with 54 more rowsdata_demo %>%
select(-plot, -yld, -don, -fdk) # another way to achieve the same thing as the previous example, the '-' says to not select those variables## # A tibble: 64 × 5
## trt var blk sev inc
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 A R 1 1.95 35
## 2 A R 1 1.2 20
## 3 A R 2 0.9 20
## 4 A R 2 4.05 50
## 5 A R 3 1.1 15
## 6 A R 3 1.8 10
## 7 A R 4 1.4 25
## 8 A R 4 0.45 10
## 9 A S 1 13.3 55
## 10 A S 1 12.3 50
## # … with 54 more rowsMutate
data_demo %>%
mutate(sev_prop = sev/100, # transform yield and inc from a percentage to a proportion and add those columns to the database
inc_prop = inc/100) ## # A tibble: 64 × 11
## plot trt var blk sev inc yld don fdk sev_prop inc_prop
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 107 A R 1 1.95 35 86.6 0.11 4 0.0195 0.35
## 2 109 A R 1 1.2 20 80.3 0.15 4 0.012 0.2
## 3 204 A R 2 0.9 20 81.1 0 42 0.009 0.2
## 4 214 A R 2 4.05 50 85.1 0.07 25 0.0405 0.5
## 5 305 A R 3 1.1 15 84.8 0 29 0.011 0.15
## 6 316 A R 3 1.8 10 93.7 0 24 0.018 0.1
## 7 406 A R 4 1.4 25 84.5 0.06 37 0.014 0.25
## 8 412 A R 4 0.45 10 84.8 0.07 42 0.0045 0.1
## 9 108 A S 1 13.3 55 92.3 0.42 NA 0.133 0.55
## 10 110 A S 1 12.3 50 103. 0.26 NA 0.123 0.5
## # … with 54 more rowsdata_demo %>%
mutate(yld = yld*67.25, # to convert yield in bushels per acre to kilograms per hectare. In this case, note that we replace the original values of yld with the new values
trt_var = paste0(trt, "_", var)) # combine two variables (trt and var) into a single variable and create a new column## # A tibble: 64 × 10
## plot trt var blk sev inc yld don fdk trt_var
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 107 A R 1 1.95 35 5824. 0.11 4 A_R
## 2 109 A R 1 1.2 20 5400. 0.15 4 A_R
## 3 204 A R 2 0.9 20 5454. 0 42 A_R
## 4 214 A R 2 4.05 50 5723. 0.07 25 A_R
## 5 305 A R 3 1.1 15 5703. 0 29 A_R
## 6 316 A R 3 1.8 10 6301. 0 24 A_R
## 7 406 A R 4 1.4 25 5683. 0.06 37 A_R
## 8 412 A R 4 0.45 10 5703. 0.07 42 A_R
## 9 108 A S 1 13.3 55 6207. 0.42 NA A_S
## 10 110 A S 1 12.3 50 6920. 0.26 NA A_S
## # … with 54 more rowsSummarize
data_demo %>%
group_by(trt) %>% # first group the variables by the trt values
summarise(sev = mean(sev), # apply the functions mean, max (maximum) and sd (standard deviation) to create summaries by trt
inv = max(inc),
yld = sd(yld))## # A tibble: 4 × 4
## trt sev inv yld
## <chr> <dbl> <dbl> <dbl>
## 1 A 3.94 60 7.79
## 2 B 1.64 35 7.19
## 3 C 0.572 20 6.67
## 4 D 0.438 40 7.13data_demo %>%
group_by(var, trt) %>% # it is possible to group multiple variables, look at the differences with the first example
summarise(sev = mean(sev),
inv = max(inc),
yld = sd(yld))## `summarise()` has grouped output by 'var'. You can override using the `.groups`
## argument.## # A tibble: 8 × 5
## # Groups: var [2]
## var trt sev inv yld
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 R A 1.61 50 4.07
## 2 R B 1.7 30 3.04
## 3 R C 0.475 20 3.94
## 4 R D 0.431 40 3.98
## 5 S A 6.28 60 3.79
## 6 S B 1.58 35 4.69
## 7 S C 0.669 15 5.72
## 8 S D 0.444 20 2.82And more (reshape)
# For some analyses and plots, we may want to reshape our data and
# we can do that using the functions pivot_longer() and pivot_wider()
data_longer <- data_demo %>%
select(-plot) %>% # remove an extra var (= plot)
pivot_longer(cols = -c(trt, var, blk), # columns that should not be reshaped as we change the database format
names_to = "variables", # name the new column for the variables which gathered
values_to = "values") # name for the column where the data are provided
data_longer## # A tibble: 320 × 5
## trt var blk variables values
## <chr> <chr> <dbl> <chr> <dbl>
## 1 A R 1 sev 1.95
## 2 A R 1 inc 35
## 3 A R 1 yld 86.6
## 4 A R 1 don 0.11
## 5 A R 1 fdk 4
## 6 A R 1 sev 1.2
## 7 A R 1 inc 20
## 8 A R 1 yld 80.3
## 9 A R 1 don 0.15
## 10 A R 1 fdk 4
## # … with 310 more rowsExport outputs
After working with your data, you probably want to create a table for
your manuscript or report. There is many packages for exporting data in
an excel file (.xlsx). In the following example, we will
use the packages openxlsx.
# Export with openxlsx package
library(openxlsx)
openxlsx::write.xlsx(data_longer, # File that we want export
file = "1_intro_to_R/data/intro_r/example_output.xlsx", # location and name of our .xlsx
sheetName="First_example", # name of sheet
append=FALSE) # If need to add to an existing file## Warning in file.create(to[okay]): cannot create file
## '1_intro_to_R/data/intro_r/example_output.xlsx', reason 'No such file or
## directory'two_data_frame <- list('ex_1' = data_demo, 'ex_2' = data_longer)
openxlsx::write.xlsx(two_data_frame, file = "1_intro_to_R/data/intro_r/two_sheets.xlsx")## Warning in file.create(to[okay]): cannot create file
## '1_intro_to_R/data/intro_r/two_sheets.xlsx', reason 'No such file or directory'